No Installation Required, Instantly Prepare for the DP-200 exam and please click the below link to start the DP-200 Exam Simulator with a real DP-200 practice exam questions.
Use directly our on-line DP-200 exam dumps materials and try our Testing Engine to pass the DP-200 which is always updated.
- (Exam Topic 3)
Your company plans to create an event processing engine to handle streaming data from Twitter. The data engineering team uses Azure Event Hubs to ingest the streaming data.
You need to implement a solution that uses Azure Databricks to receive the streaming data from the Azure Event Hubs.
Which three actions should you recommend be performed in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.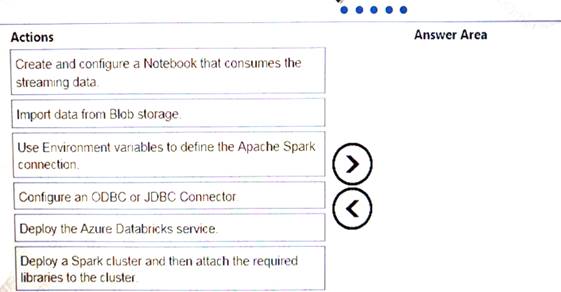
Solution: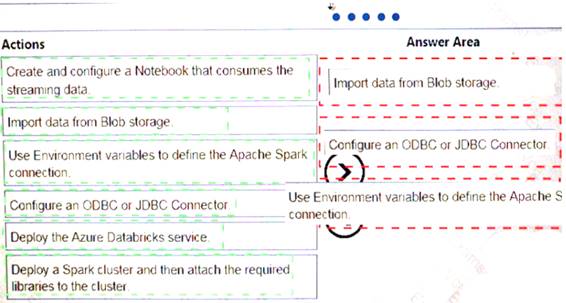
Does this meet the goal?
Correct Answer:A
- (Exam Topic 2)
You need to process and query ingested Tier 9 data.
Which two options should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Correct Answer:EF
Event Hubs provides a Kafka endpoint that can be used by your existing Kafka based applications as an alternative to running your own Kafka cluster.
You can stream data into Kafka-enabled Event Hubs and process it with Azure Stream Analytics, in the following steps: Create a Kafka enabled Event Hubs namespace. Create a Kafka client that sends messages to the event hub. Create a Stream Analytics job that copies data from the event hub into an Azure blob storage. Scenario:
Create a Kafka enabled Event Hubs namespace. Create a Kafka client that sends messages to the event hub. Create a Stream Analytics job that copies data from the event hub into an Azure blob storage. Scenario:
Tier 9 reporting must be moved to Event Hubs, queried, and persisted in the same Azure region as the company’s main office
References:
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-kafka-stream-analytics
- (Exam Topic 3)
Each day, company plans to store hundreds of files in Azure Blob Storage and Azure Data Lake Storage. The company uses the parquet format.
You must develop a pipeline that meets the following requirements:  Process data every six hours Offer interactive data analysis capabilities Offer the ability to process data using solid-state drive (SSD) caching Use Directed Acyclic Graph(DAG) processing mechanisms Provide support for REST API calls to monitor processes
Process data every six hours Offer interactive data analysis capabilities Offer the ability to process data using solid-state drive (SSD) caching Use Directed Acyclic Graph(DAG) processing mechanisms Provide support for REST API calls to monitor processes  Provide native support for Python Integrate with Microsoft Power BI
Provide native support for Python Integrate with Microsoft Power BI
You need to select the appropriate data technology to implement the pipeline. Which data technology should you implement?
Correct Answer:B
Storm runs topologies instead of the Apache Hadoop MapReduce jobs that you might be familiar with. Storm topologies are composed of multiple components that are arranged in a directed acyclic graph (DAG). Data flows between the components in the graph. Each component consumes one or more data streams, and can optionally emit one or more streams.
Python can be used to develop Storm components. References:
https://docs.microsoft.com/en-us/azure/hdinsight/storm/apache-storm-overview
- (Exam Topic 3)
A company plans to develop solutions to perform batch processing of multiple sets of geospatial data. You need to implement the solutions.
Which Azure services should you use? To answer, select the appropriate configuration tit the answer area. NOTE: Each correct selection is worth one point.
Solution: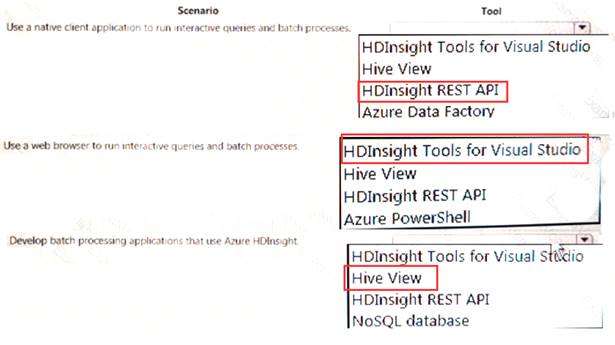
Does this meet the goal?
Correct Answer:A
- (Exam Topic 3)
You configure monitoring for a Microsoft Azure SQL Data Warehouse implementation. The implementation uses PolyBase to load data from comma-separated value (CSV) files stored in Azure Data Lake Gen 2 using an external table.
Files with an invalid schema cause errors to occur. You need to monitor for an invalid schema error. For which error should you monitor?
Correct Answer:C
Customer Scenario:
SQL Server 2016 or SQL DW connected to Azure blob storage. The CREATE EXTERNAL TABLE DDL points to a directory (and not a specific file) and the directory contains files with different schemas.
SSMS Error:
Select query on the external table gives the following error: Msg 7320, Level 16, State 110, Line 14
Cannot execute the query "Remote Query" against OLE DB provider "SQLNCLI11" for linked server "(null)". Query aborted-- the maximum reject threshold (0 rows) was reached while reading from an external source: 1 rows rejected out of total 1 rows processed.
Possible Reason:
The reason this error happens is because each file has different schema. The PolyBase external table DDL when pointed to a directory recursively reads all the files in that directory. When a column or data type mismatch happens, this error could be seen in SSMS.
Possible Solution:
If the data for each table consists of one file, then use the filename in the LOCATION section prepended by the directory of the external files. If there are multiple files per table, put each set of files into different directories in Azure Blob Storage and then you can point LOCATION to the directory instead of a particular file. The latter suggestion is the best practices recommended by SQLCAT even if you have one file per table.